- Nov. 2024: Invited as a reviewer for the ICME2025 conference.
- Aug. 2024: Incorporated a project on automotive maintenance inspection using a multimodal large model.
- Jul. 2024: Joined the SpConv operator optimization project based on MetaX MXMACA computing platform.
- Jun. 2024: Approved for the Chinese Software Copyright “Dermatology Clinical Feature Detection and Diagnosis System”.
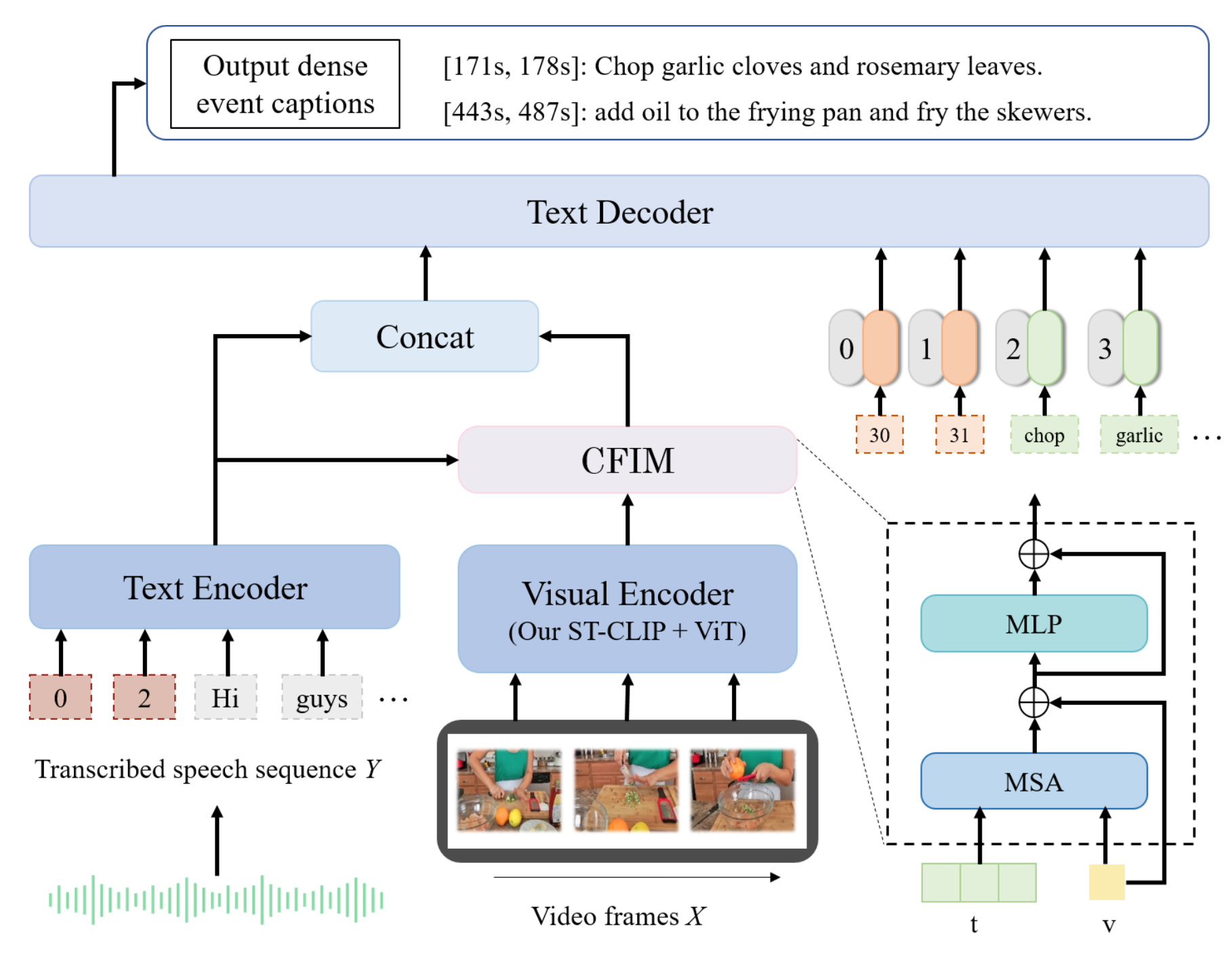
- May 2024: The paper “ST-CLIP” has been accepted at ICIC 2024 conference.
- Jan. 2024: Invited as a reviewer for the ICME2024 conference.
- Dec. 2023: Joined the school-enterprise cooperation program of Haluo Corporation, responsible for the AI speech generation part of it.
- Nov. 2023: Completed the Transformer Heterogeneous Bisheng C++ Arithmetic Development Project of Huawei Crowd Intelligence Program, and was responsible for the Adam Arithmetic part of the project.
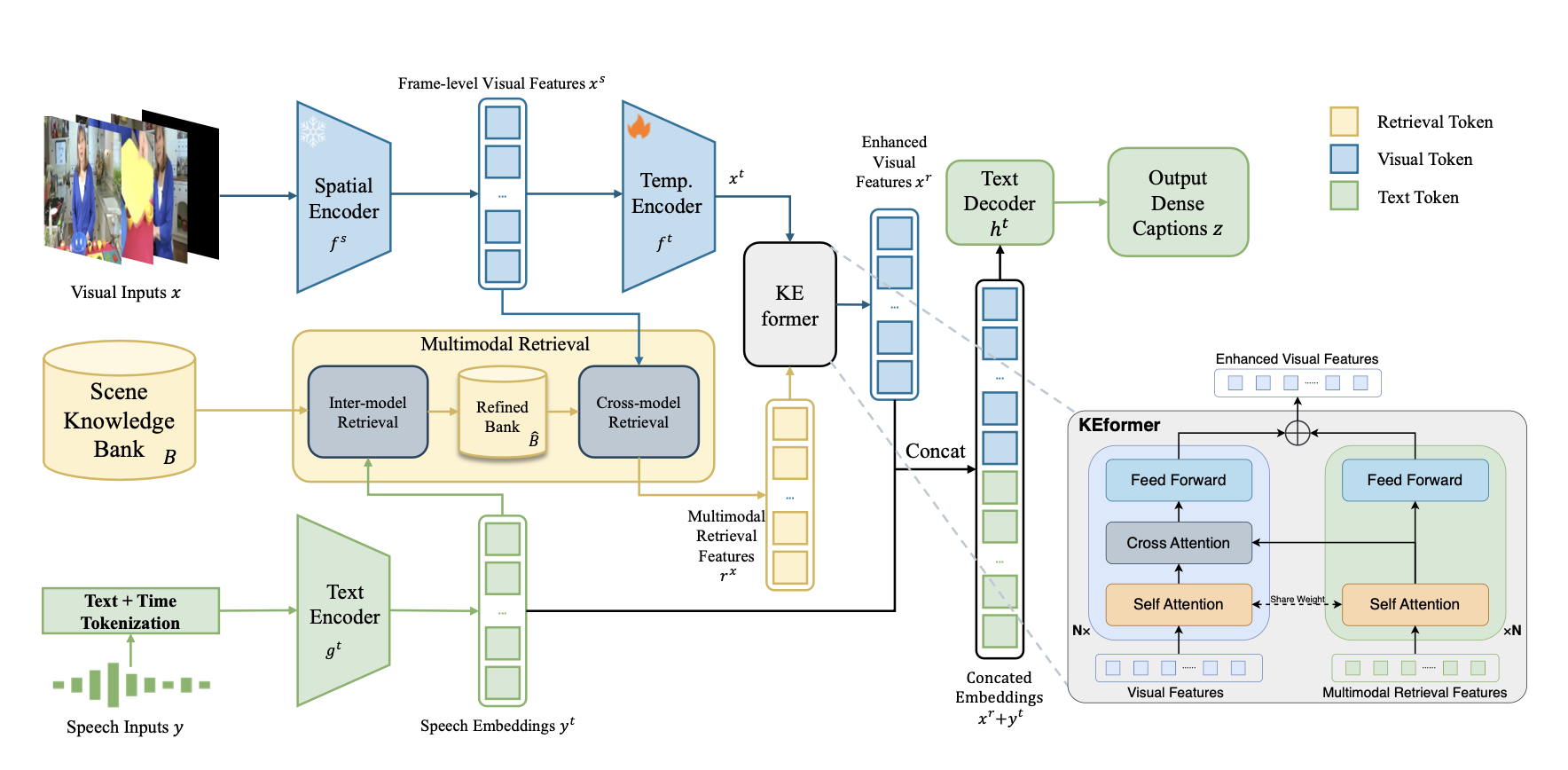
- Sept. 2023: Join a video understanding project, the main direction is dense video captioning.

Hello, I'm Mingru Huang
I am a Master’s degree student in Wuhan University of Technology. I’m interested in research in computer vision, particularly video understanding. My research includes video Q&A, video-text retrieval, and video captioning. Meanwhile, I also have some research and practice in large language models, prompt engineering, basic operator development and optimization, knowledge graphs, and Q&A systems. I hope to make a generalized multimodal video model that is affordable, secure and trustworthy for everyone.